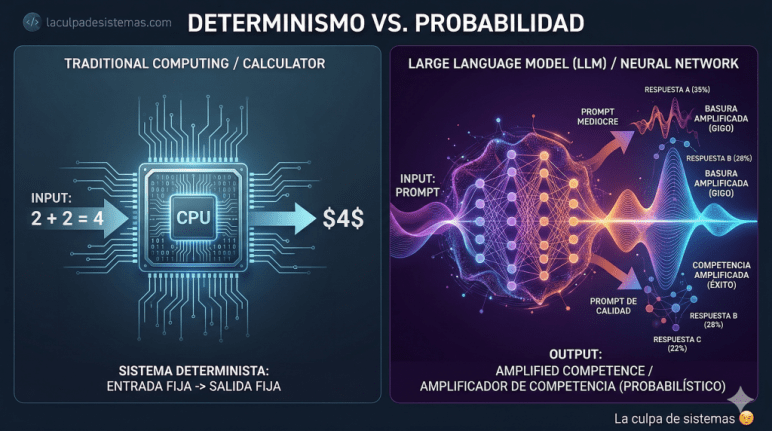
Existe una frustración latente al interactuar con modelos de lenguaje: la sensación de que son imprecisos o que «alucinan». Esta fricción nace de un error en nuestra arquitectura mental al tratar a los LLM (una fracción del ecosistema de la IA que incluye redes neuronales y estructuras de árbol) como software tradicional. Esperamos respuestas deterministas donde solo hay probabilidad. Un LLM no es una herramienta de cálculo; es un amplificador de señal.
La falacia del determinismo
Históricamente, nuestra relación con las máquinas ha sido binaria: si 2€ + 2€ no da 4€, el sistema está roto. Sin embargo, un LLM se sitúa más cerca del comportamiento humano que del silicio puro. Al haber sido entrenados con el rastro digital de nuestra propia lógica y contenido, han heredado nuestra capacidad de razonar, pero también nuestra falibilidad. Esta naturaleza probabilística explica por qué la misma entrada no siempre garantiza la misma salida; el modelo no calcula, sino que predice el paso más probable.
La Ley de la Amplificación (GIGO)
Como amplificador, el LLM opera bajo el principio GIGO (Garbage In, Garbage Out):
- Input mediocre: si alimentas el modelo con una premisa pobre o «mierda», obtendrás «mierda amplificada» e industrializada.
- Input de calidad: si introduces procesos bien definidos, la IA actúa como un catalizador que devuelve resultados optimizados que antes requerían semanas de esfuerzo.
Teniendo en cuenta el GIGO y asumiendo que el objetivo es obtener calidad, las dos premisas fundamentales para dominar esta herramienta son cambiar nuestra mentalidad hacia el trabajo por objetivos y mantener una higiene estricta del entorno de trabajo mediante contextos limpios.
1. Cambio de mentalidad: gestión por objetivos
El primer pilar de esta eficiencia es dejar de decir «cómo» se hacen las cosas para empezar a definir «dónde» queremos llegar. El profesional deja de ser un ejecutor para convertirse en un director de orquesta que valida resultados.
| Dimensión | Ejecución Manual | Modelo IA + Revisión | Mejora Estimada |
| Tiempo de ciclo | 4 semanas | 15 min (Gen) + 4 h (Revisión) | ~98,0% |
| Tasa de error | 10,0% | 2,0% | ~80,0% |
| Enfoque | El proceso («cómo») | El resultado («qué») | N/A |
2. Higiene operativa: la ventana de contexto
El segundo pilar es la gestión de la «memoria de trabajo» del modelo. El LLM opera sobre una ventana de contexto que almacena todo lo dicho en la conversación.
- El riesgo del error persistente: si un dato erróneo o una instrucción ambigua contamina la ventana, el modelo la usará como base para todas sus predicciones futuras dentro de ese chat.
- Protocolo Clean Slate: ante un error estructural o un hilo «envenenado», la estrategia más eficiente es extraer la información relevante, cerrar el chat y reiniciar un contexto limpio. No se debe intentar corregir infinitamente un hilo contaminado.
El fin de la ambigüedad
La nitidez del resultado es directamente proporcional a la claridad de la instrucción. Pedir «un informe» o «una foto» es enviar ruido al amplificador. Para obtener resultados de nivel senior, es imperativo definir roles, objetivos y restricciones técnicas precisas. El LLM no ha venido a sustituir el criterio técnico, sino a exigir que el operador sea mucho más agudo en su comunicación.
Espero que os sea útil, suscribiros para que os lleguen avisos de la próxima entrada y no dudéis en comentar o mandar un mensaje con cualquier consulta, aportación o inquietud que tengáis…
… y si algo sale mal… La Culpa de Sistemas 😉
